
Ssoon
AWS EKS - Observability - Container Insights 본문
CloudNet@ 팀의 AWS EKS Workshop Study 2기 - 4주차
# EKS Workshop 참고- Workshop 실습 환경 준비
더보기

실습 환경 다음과 같이 변경

- 오픈 텔레메트리용 AWS 배포용 EKS 관리형 애드온을 설치
- ADOT 수집기가 CloudWatch에 액세스할 수 있도록 IAM 역할 생성
- 테라폼실습구성링크
Amazon CloudWatch Container Insights
- Kubernetes 기반의 Amazon EKS(Elastic Kubernetes Service) 클러스터에서 컨테이너 환경의 모니터링을 담당
- Container Insights는 Amazon ECS(Amazon Elastic Container Service), Amazon EKS(Amazon Elastic Kubernetes Service) 및 Amazon EC2의 Kubernetes 플랫폼에서 사용 / Amazon ECS 지원에는 Fargate에 대한 지원이 포함
- Container Insights가 수집하는 메트릭에 대해 CloudWatch 알람을 설정
- Container Insights가 수집하는 메트릭은 CloudWatch 자동 대시보드에서 사용
- CloudWatch 로그 인사이트를 사용하여 컨테이너 성능 및 로그 데이터를 분석하고 문제를 해결
- 컨테이너 및 애플리케이션 모니터링:
- AWS EKS Container Insights는 Kubernetes 클러스터에서 실행 중인 컨테이너와 애플리케이션의 성능을 실시간으로 모니터
- 컨테이너의 CPU, 메모리, 네트워크 사용률 및 로그 데이터를 수집하여 시각화
- 통합된 모니터링 대시보드:
- EKS Container Insights는 Amazon CloudWatch의 대시보드와 통합되어 통합된 모니터링 대시보드를 제공
- 대시보드에서는 클러스터, 노드, 컨테이너, 애플리케이션의 상태 및 성능에 대한 요약 정보를 제공
- 성능 데이터 수집 및 분석:
- 서버리스 모니터링을 위해 AWS X-Ray와 통합되어 성능 데이터를 수집하고 분석
- 로그, 이벤트 및 예외 정보를 수집하여 애플리케이션의 성능 향상을 위한 인사이트를 제공
- 경고 및 알림:
- EKS Container Insights는 CloudWatch Alarm과 통합되어 사용자가 정의한 경고 및 알림을 설정
- 사용자가 정의한 임계값을 초과하는 경우 알림을 받아 잠재적인 문제를 신속하게 파악하고 조치
- 스케일링 및 최적화:
- 모니터링 데이터를 기반으로 자동 스케일링 및 리소스 최적화를 수행
- 리소스 사용률을 실시간으로 모니터링하여 필요에 따라 자동으로 확장하거나 축소
💠 오픈 텔레메트리용 AWS 배포를 사용하여 컨테이너 인사이트 활성화하기
- EKS 클러스터에 대해 ADOT 수집기를 사용하여 CloudWatch 컨테이너 인사이트 메트릭을 활성화하는 방법
- ADOT 수집기에 필요한 권한을 허용하는 리소스를 생성
- 수집기에 Kubernetes API에 액세스할 수 있는 권한을 부여하는 ClusterRole부터 시작
- 관리형 IAM 정책인 CloudWatchAgentServerPolicy 를 사용하여 서비스 계정에 대한 IAM 역할을 통해 수집기에 필요한 IAM 권한을 제공
- IAM 역할은 수집기에 대한 서비스 계정에 추가
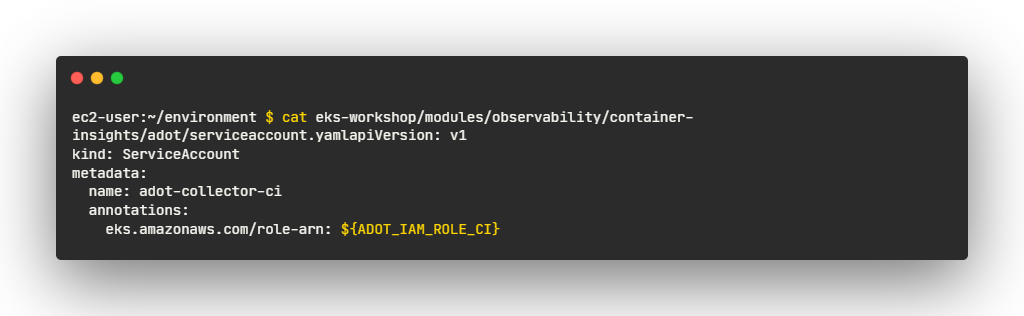
- 리소스 생성
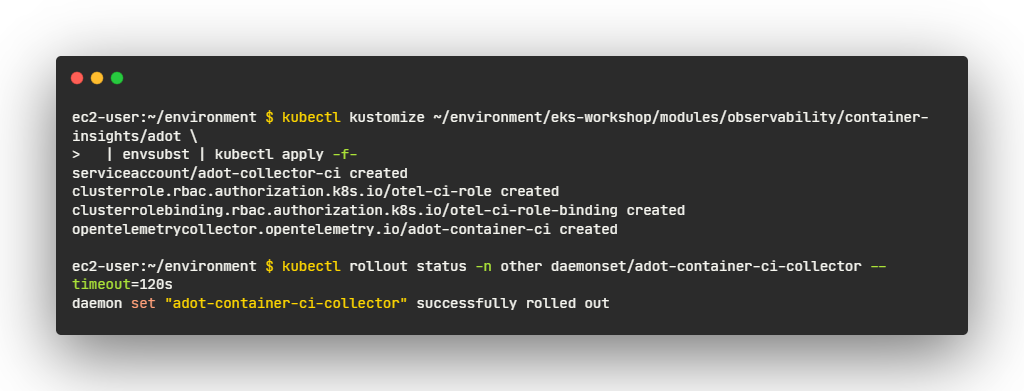
- 수집기의 사양 확인

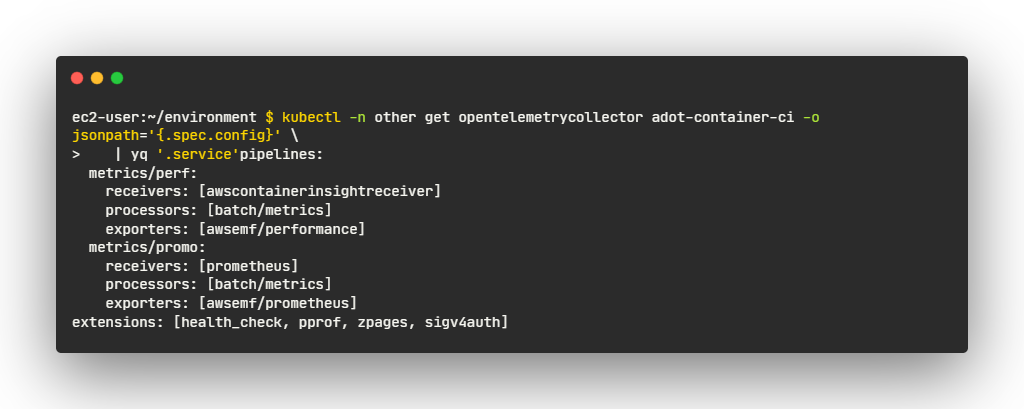
- OpenTelemetry 수집기 구성
- Receivers
- 임베디드 메트릭 형식을 사용하여 성능 로그 이벤트를 수집하도록 설계된 컨테이너 인사이트 수신기
- Processors
- 메트릭을 60초 간격으로 일괄 처리
- Exporters
- CloudWatch API로 메트릭을 전송하는 CloudWatch EMF 익스포터
- Receivers
- 이 수집기는 또한 각 노드에서 실행되는 수집기 에이전트와 함께 데몬셋으로 실행되도록 구성

- 실행 중인 컨테이너 인사이트 메트릭을 수집하는 ADOT 수집기 파드를 검사하면 이를 확인
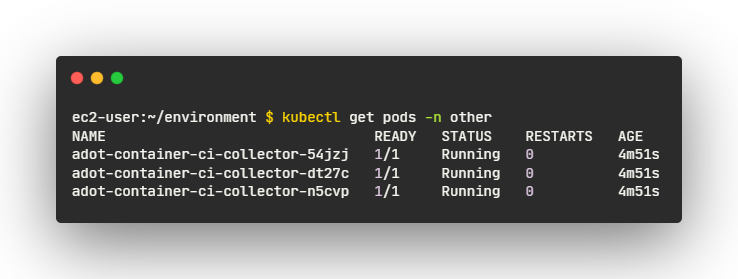
- 실행 중인 상태의 여러 파드가 포함되어 수집기가 실행 중이며 클러스터에서 메트릭을 수집하고 있는 것
- 수집기는 aws/containerinsights/cluster-name/performance 라는 로그 그룹을 생성하고 메트릭 데이터를 EMF 형식의 성능 로그 이벤트로 전송
💠 Amazon CloudWatch의 컨테이너 인사이트 메트릭
- CloudWatch를 사용하여 컨테이너 인사이트 메트릭을 시각화
- CloudWatch에 데이터가 표시되기 시작하려면 몇 분 정도 걸릴 수 있습니다.
- 메트릭을 보려면 먼저 CloudWatch 콘솔을 열고 컨테이너 인사이트로 이동
- 페이지 상단의 드롭다운 메뉴에서 성능 모니터링을 선택하고, 리소스 유형을 선택
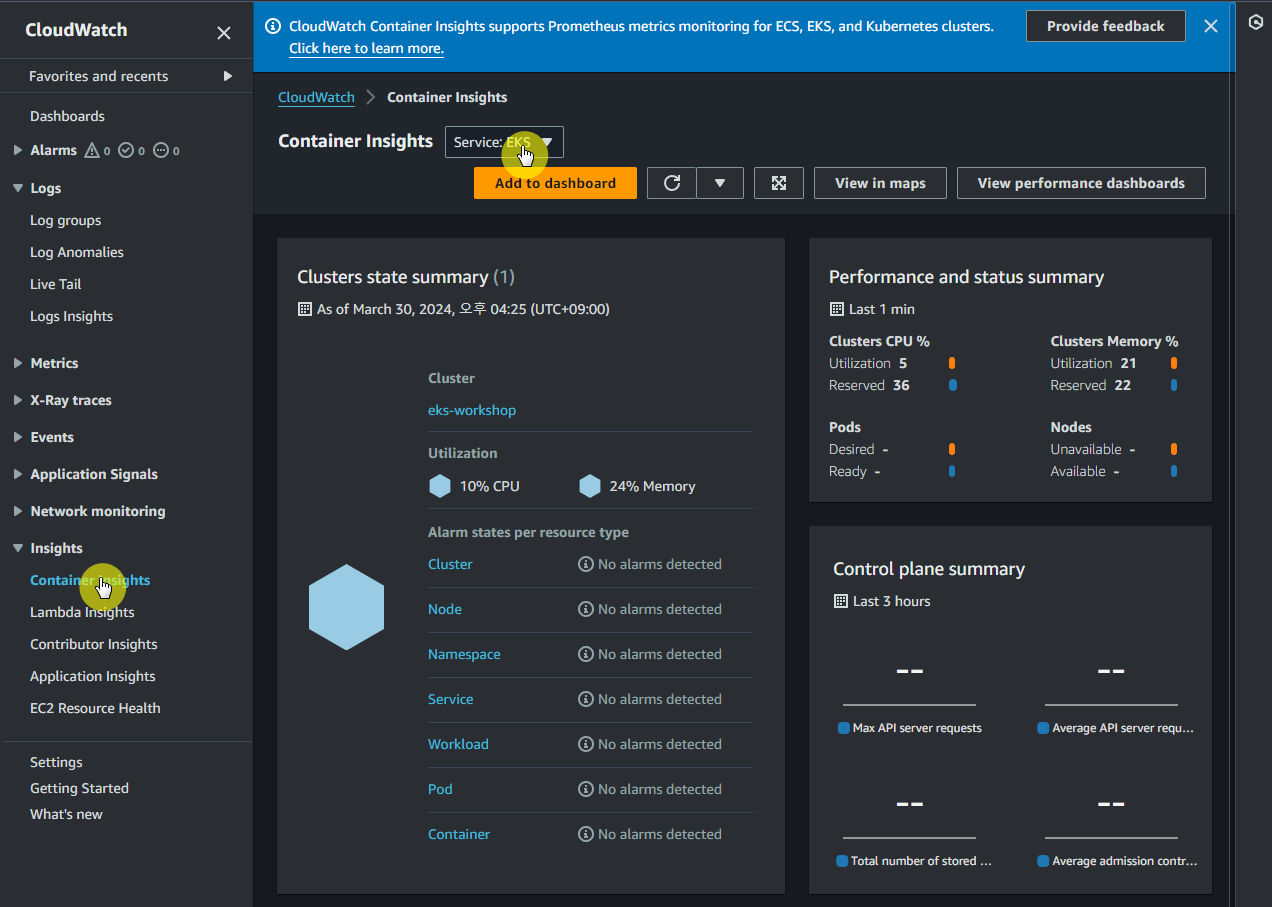
- 컨테이너 인사이트가 수집하는 모든 메트릭에 CloudWatch 알람을 설정 가능
💠 CloudWatch 로그 인사이트가 포함된 컨테이너 인사이트 데이터
- Container Insights는 CloudWatch 로그에 저장된 임베디드 메트릭 형식과 함께 성능 로그 이벤트를 사용하여 메트릭을 수집
- CloudWatch는 CloudWatch 콘솔에서 볼 수 있는 로그에서 여러 메트릭을 자동으로 생성
- CloudWatch 로그 인사이트 쿼리를 사용하여 수집된 성능 데이터에 대한 심층 분석을 수행
- 로그 그룹을 선택하고 쿼리를 실행하면 CloudWatch Logs Insights가 로그 그룹의 데이터에서 필드를 자동으로 감지하여 오른쪽 창에 검색된 필드에 표시
- 로그 그룹에 있는 로그 이벤트의 시간 경과에 따른 막대 그래프도 표시
- 막대 그래프는 테이블에 표시된 이벤트뿐만 아니라 쿼리 및 시간 범위와 일치하는 로그 그룹 내 이벤트의 분포를 표시
- performance로 끝나는 EKS 클러스터의 로그 그룹을 선택
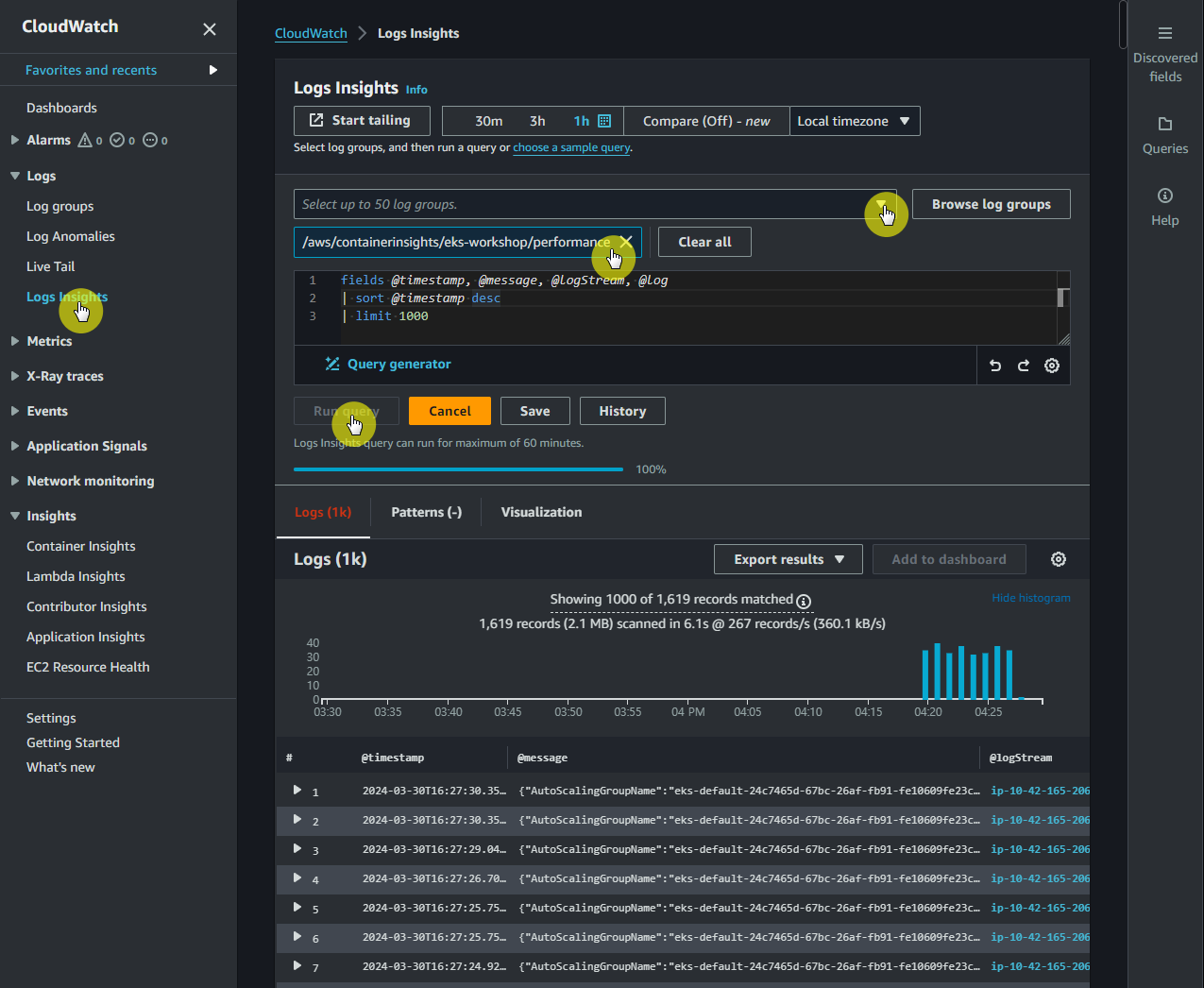
- 쿼리 편집기에서 기본 쿼리를 다음 쿼리로 바꾸고 쿼리 실행을 선택
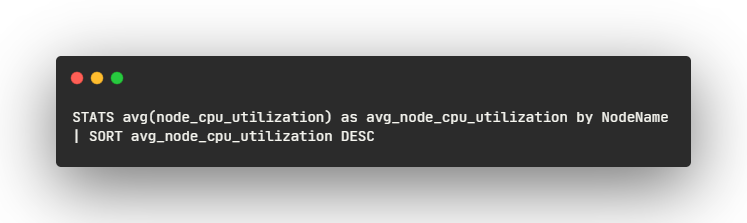
- STATS avg(node_cpu_utilization) as avg_node_cpu_utilization by NodeName:
- 메트릭 데이터를 쿼리하여 처리
- avg(node_cpu_utilization)은 node_cpu_utilization 메트릭의 평균 값을 계산하는 것을 의미
- 각 노드에서 CPU 사용률의 평균 값을 계산
- as avg_node_cpu_utilization은 계산된 평균 값을 avg_node_cpu_utilization이라는 새로운 이름으로 할당
- by NodeName은 결과를 NodeName 레이블을 기준으로 그룹화
- 각 노드의 CPU 사용률에 대한 데이터를 노드별로 그룹화
- | SORT avg_node_cpu_utilization DESC:
- avg_node_cpu_utilization 값을 기준으로 내림차순으로 정렬
- CPU 사용률이 높은 순서대로 결과가 나열
각 노드에서의 CPU 사용률을 평균내고, 해당 값을 기준으로 내림차순으로 정렬

- 다음 쿼리로 바꾸고 쿼리 실행을 선택
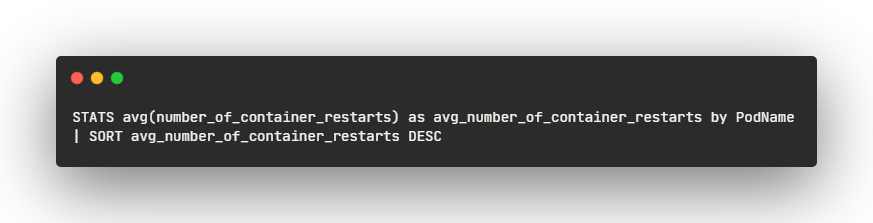
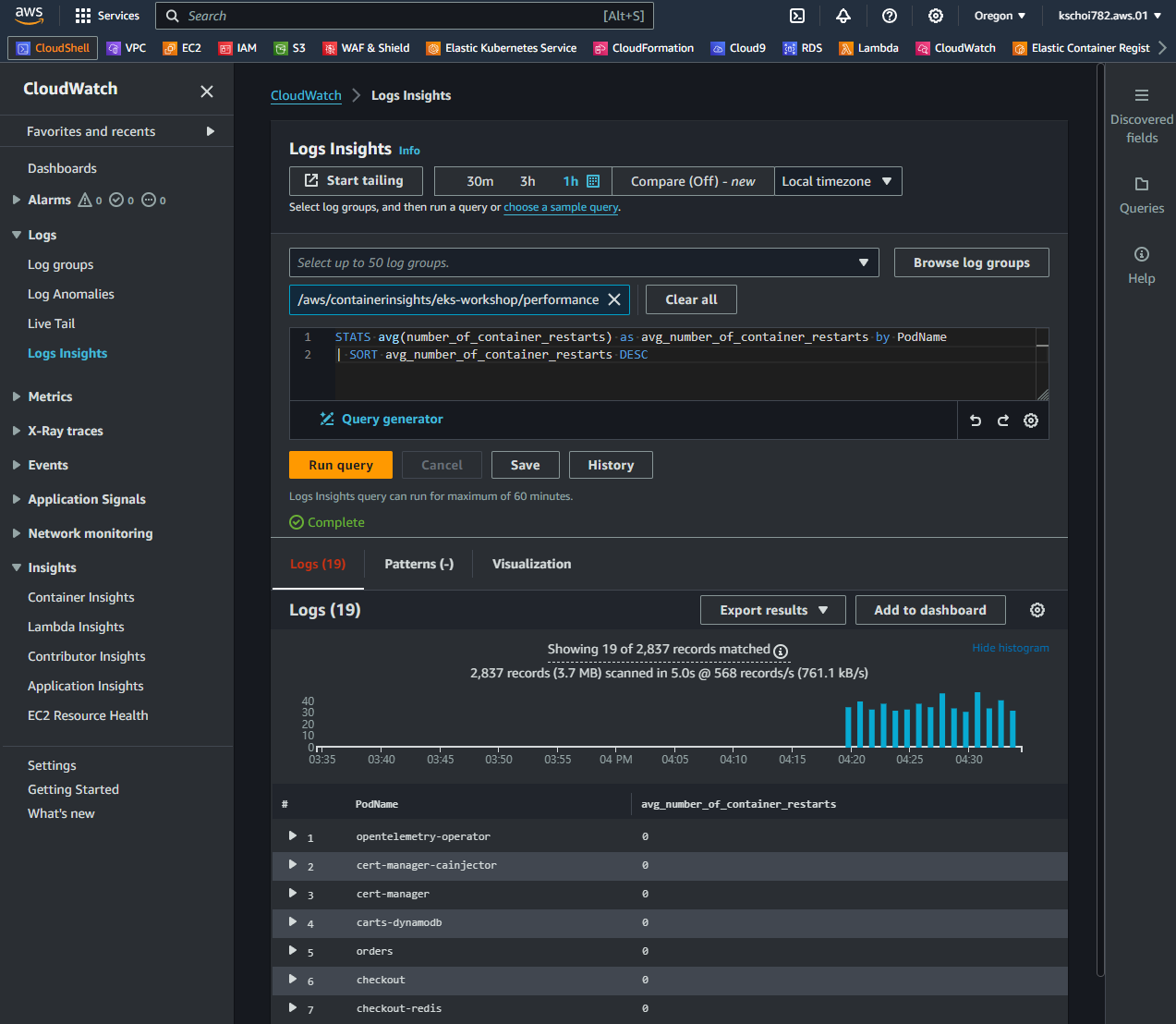
- STATS avg(number_of_container_restarts) as avg_number_of_container_restarts by PodName:
- 이 부분은 메트릭 데이터를 쿼리하여 처리
- avg(number_of_container_restarts)는 number_of_container_restarts 메트릭의 평균 값을 계산
- 각 Pod에서 컨테이너 재시작 횟수의 평균 값을 계산
- as avg_number_of_container_restarts은 계산된 평균 값을 avg_number_of_container_restarts이라는 새로운 이름으로 할당
- by PodName은 결과를 PodName 레이블을 기준으로 그룹화
- 각 Pod의 컨테이너 재시작 횟수에 대한 데이터를 Pod별로 그룹화
- | SORT avg_number_of_container_restarts DESC:
- 이 부분은 결과를 정렬합니다.
- avg_number_of_container_restarts 값을 기준으로 내림차순으로 정렬합니다. 이렇게 하면 컨테이너 재시작 횟수가 많은 순서대로 결과가 나열됩니다.
각 Pod에서의 컨테이너 재시작 횟수의 평균을 계산하고, 해당 값을 기준으로 내림차순으로 정렬
💠 Amazon CloudWatch의 애플리케이션 메트릭
- 워크로드에 의해 노출된 메트릭에 대한 인사이트를 얻고 Amazon CloudWatch Insights Prometheus를 사용하여 이러한 메트릭을 시각화하는 방법
- Java 힙 메트릭 또는 데이터베이스 연결 풀 상태와 같은 시스템 메트릭
- 비즈니스 KPI와 관련된 애플리케이션 메트릭
- OpenTelemetry용 AWS 배포를 사용하여 애플리케이션 메트릭을 수집하고 Amazon CloudWatch를 사용하여 메트릭을 시각화하는 방법
- 주문 서비스에서 이러한 메트릭의 예
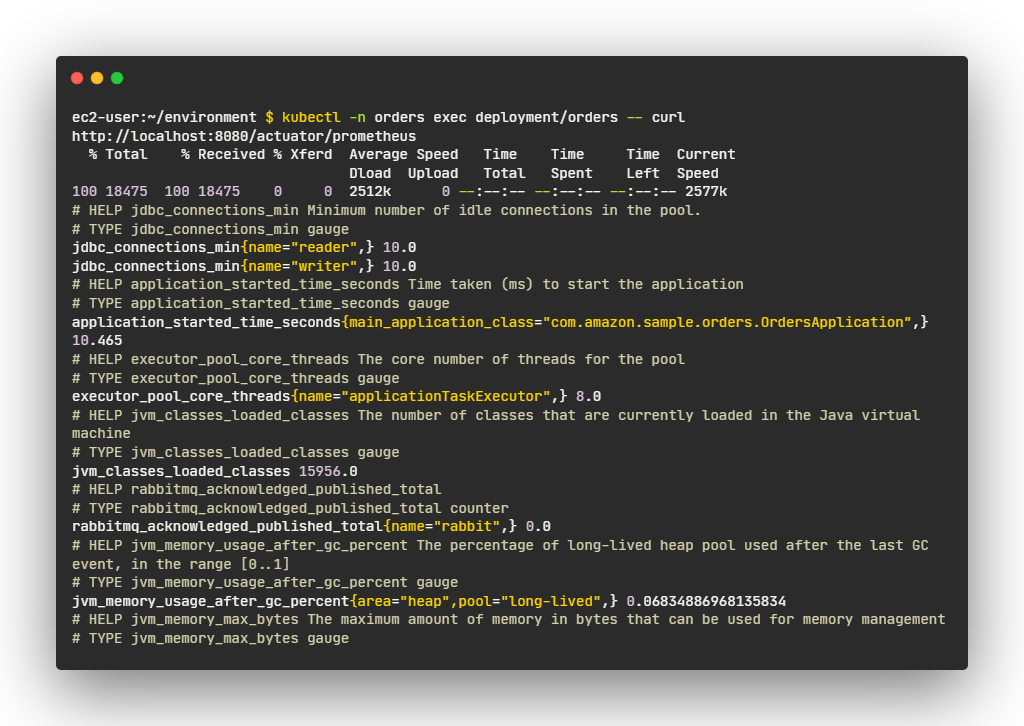
- watch_orders_total - 애플리케이션 메트릭 - 리테일 스토어를 통해 이루어진 주문 수
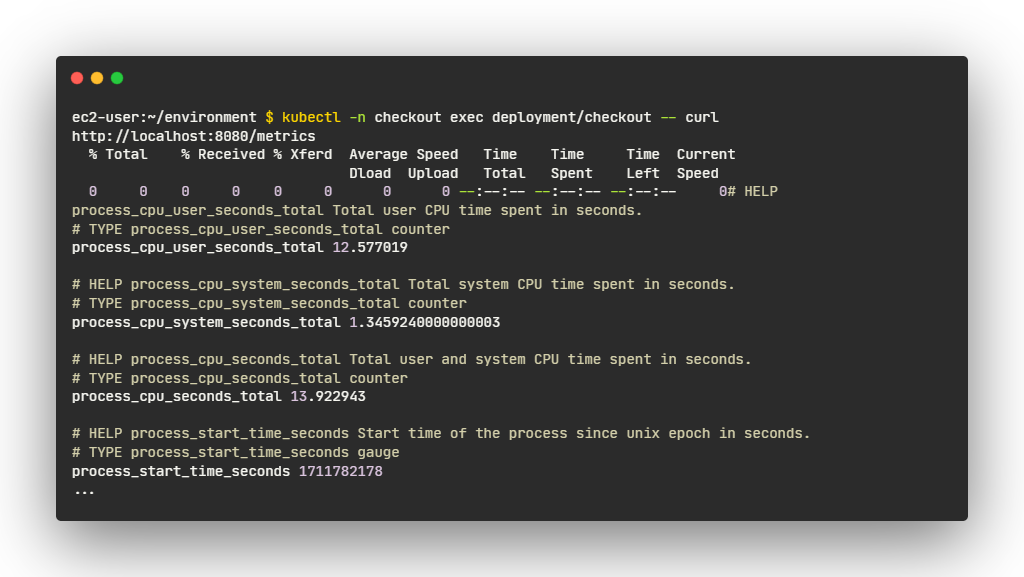
- 결제 서비스와 같은 다른 구성 요소와 유사한 요청을 실행할 수 있습니다:
- 모든 구성 요소에서 메트릭을 수집하고 주문이 접수된 수를 표시하는 Amazon CloudWatch 대시보드를 구축하기 위해 OpenTelemetry용 AWS 배포와 함께 CloudWatch Container Insights Prometheus 지원을 활용
- Prometheus와 CloudWatch 컨테이너 인사이트 Prometheus를 통합하기 위해 해결해야 할 두 가지 부분
- 첫 번째는 애플리케이션 포드에서 Prometheus의 메트릭을 가져오는 것
- 두 번째 문제는 올바른 메타데이터 세트와 함께 CloudWatch 전용 형식으로 메트릭을 노출하는 것
- 먼저 애플리케이션 포드에서 메트릭을 스크랩
- 이를 위한 OpenTelemetry 구성
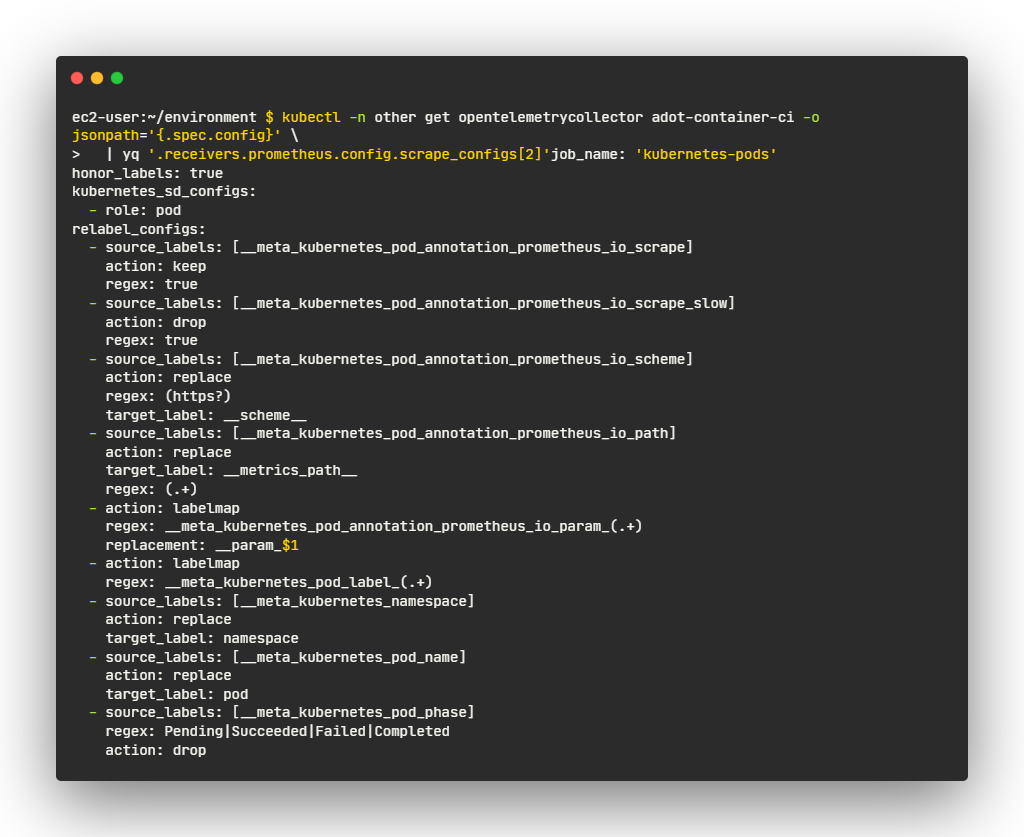
- 특정 어노테이션이 있는 모든 파드를 자동으로 검색하기 위해 Prometheus Kubernetes 서비스 검색 메커니즘을 활용
- 이 특정 구성은 prometheus.io/scrape 어노테이션이 있는 모든 파드를 검색하고 네임스페이스 및 파드 이름과 같은 Kubernetes 메타데이터로 스크랩하는 메트릭을 보강
- CloudWatch 컨테이너 인사이트 Prometheus를 지원하기 위해, 특정 차원의 메트릭을 임베디드 메트릭 형식인 EMF로 내보내기
- CloudWatch EMF 익스포터는 메트릭 데이터를 EMF를 사용하여 성능 로그 이벤트로 변환한 다음 PutLogEvents API를 사용하여 CloudWatch 로그 그룹으로 직접 전송
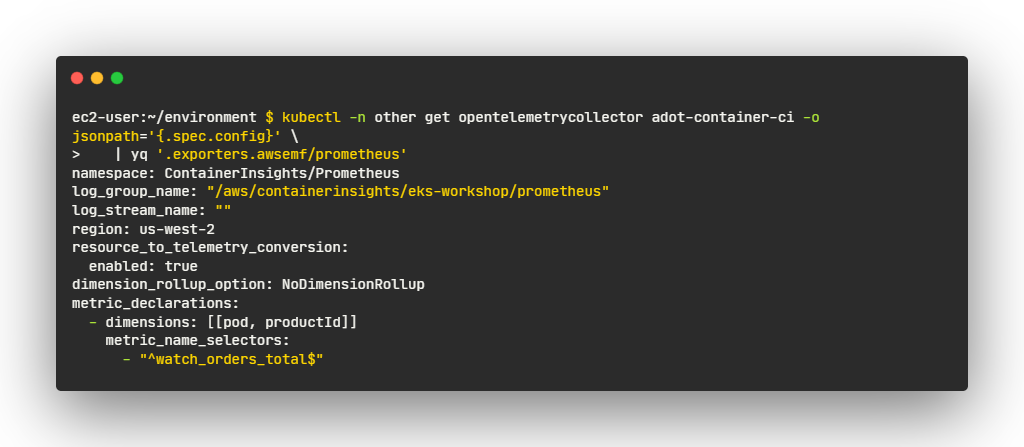
- 파이프라인은 구성 파일인 opentelemetrycollector.yaml에 정의
- 파이프라인은 OpenTelemetry 수집기의 데이터 흐름을 정의하며 메트릭 수신, 처리 및 내보내기를 포함
- 각 단계에는 여러 구성 요소가 있을 수 있으며 직렬(프로세서) 또는 병렬(수신기, 내보내기)로 실행
- 내부적으로 모든 구성 요소는 OpenTelemetry의 통합 데이터 모델을 사용하여 통신하므로 서로 다른 공급업체의 구성 요소가 함께 작동
- 수신기는 소스 시스템에서 데이터를 수집하여 내부 모델로 변환
- 프로세서는 메트릭을 필터링하고 수정
- 내보내기는 데이터를 다른 스키마로 변환하여 대상 시스템으로 보냅니다.
- 주문의 메트릭은 내보내기 구성 설정에 따라 차원 포드 및 productId를 사용하여 CloudWatch 메트릭 네임스페이스 ContainerInsights/Prometheus에서 사용할 수 있게 됩니다.
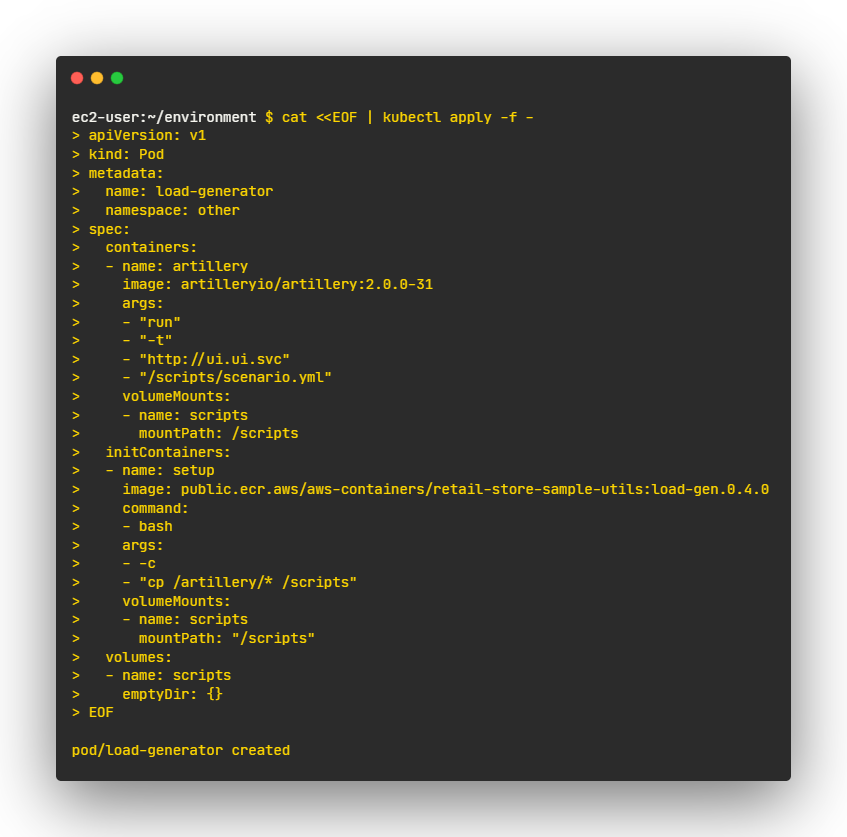
- 스크립트를 사용하여 스토어를 통해 주문하고 애플리케이션 메트릭을 생성하는 로드 생성기를 실행
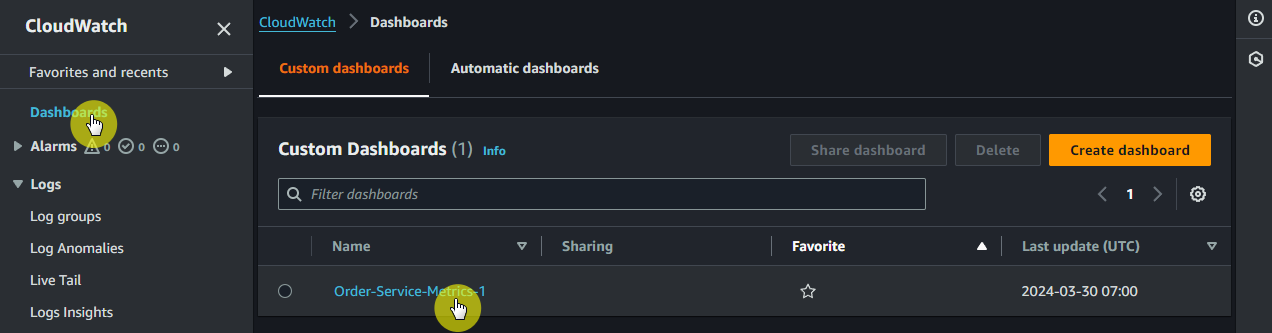
- CloudWatch 콘솔을 열고 대시보드 섹션으로 이동
- 주문-서비스-메트릭 대시보드를 선택하여 대시보드 내의 패널을 검토
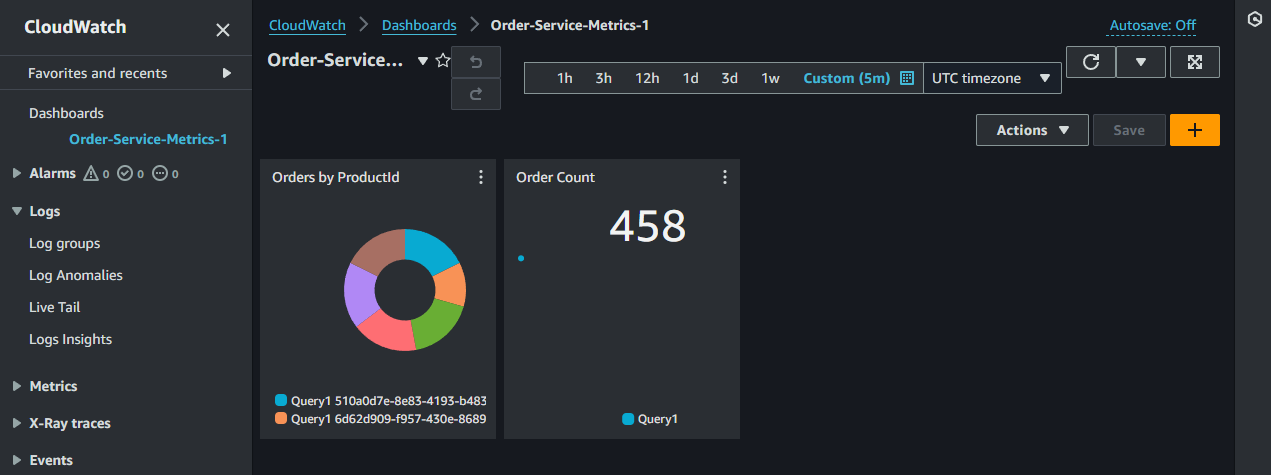
- '제품별 주문' 패널의 제목 위로 마우스를 가져가서 '편집' 버튼을 클릭하면 대시보드가 CloudWatch를 쿼리하도록 어떻게 구성되었는지 확인
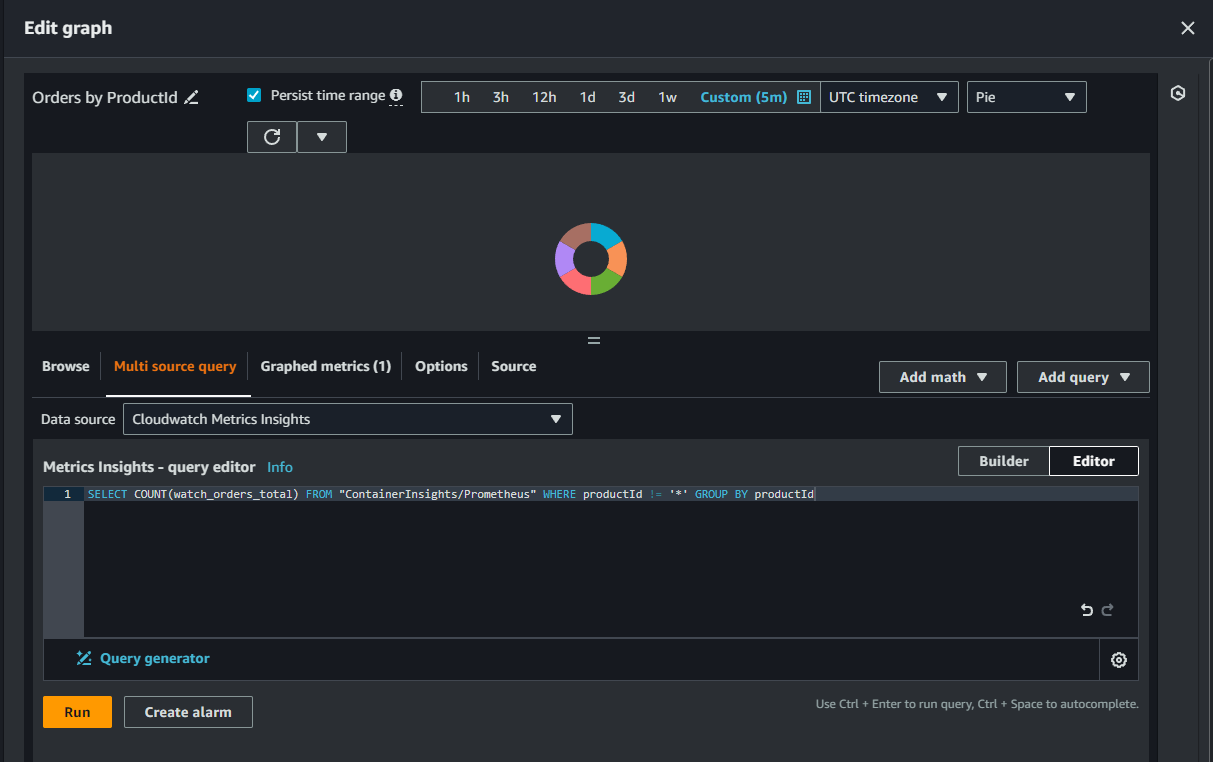

- SELECT COUNT(watch_orders_total):
- 메트릭 데이터를 쿼리하여 처리
- watch_orders_total 메트릭의 데이터를 선택하고, 해당 메트릭의 총 개수를 세는 것을 의미
- COUNT() 함수는 선택된 메트릭의 개수를 계산
- FROM "ContainerInsights/Prometheus":
- 이터를 가져올 데이터 소스를 지정
- "ContainerInsights/Prometheus"는 CloudWatch Container Insights의 Prometheus 데이터 소스를 의미
- 이 데이터 소스에서 메트릭 데이터를 가져옵니다.
- WHERE productId != '*':
- 쿼리 결과에 대한 필터링을 수행
- productId 레이블 값이 "*"(모든 값)이 아닌 경우에 해당하는 데이터만 선택
- 즉, productId 값이 특정한 경우에만 해당하는 데이터를 선택.
- GROUP BY productId:
- productId 레이블 값을 기준으로 데이터를 그룹화
- 각 그룹은 해당하는 productId 값으로 식별
각 productId에 대한 watch_orders_total 메트릭의 개수를 쿼리하고, 해당 값을 productId에 따라 그룹화하여 보여줍니다. 이를 통해 각 제품에 대한 주문의 총 수를 파악
'AWS EKS Workshop Study 2기' 카테고리의 다른 글
| AWS EKS - Autoscaling - Compute (0) | 2024.03.31 |
|---|---|
| AWS EKS - Observability - Cost visibility with Kubecost (0) | 2024.03.30 |
| AWS EKS - Observability - Open Source (0) | 2024.03.30 |
| AWS EKS - Observability - OpenSearch (0) | 2024.03.30 |
| AWS EKS - Observability - Logging in EKS (0) | 2024.03.30 |
'AWS EKS Workshop Study 2기' Related Articles
more




Comments