
Ssoon
[혼공데분] 01 데이터분석을 시작하며 - 3) 이 도서가 얼마나 인기가 좋을까요? 본문
도서 데이터 찾기
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
도서관 대출 데이터
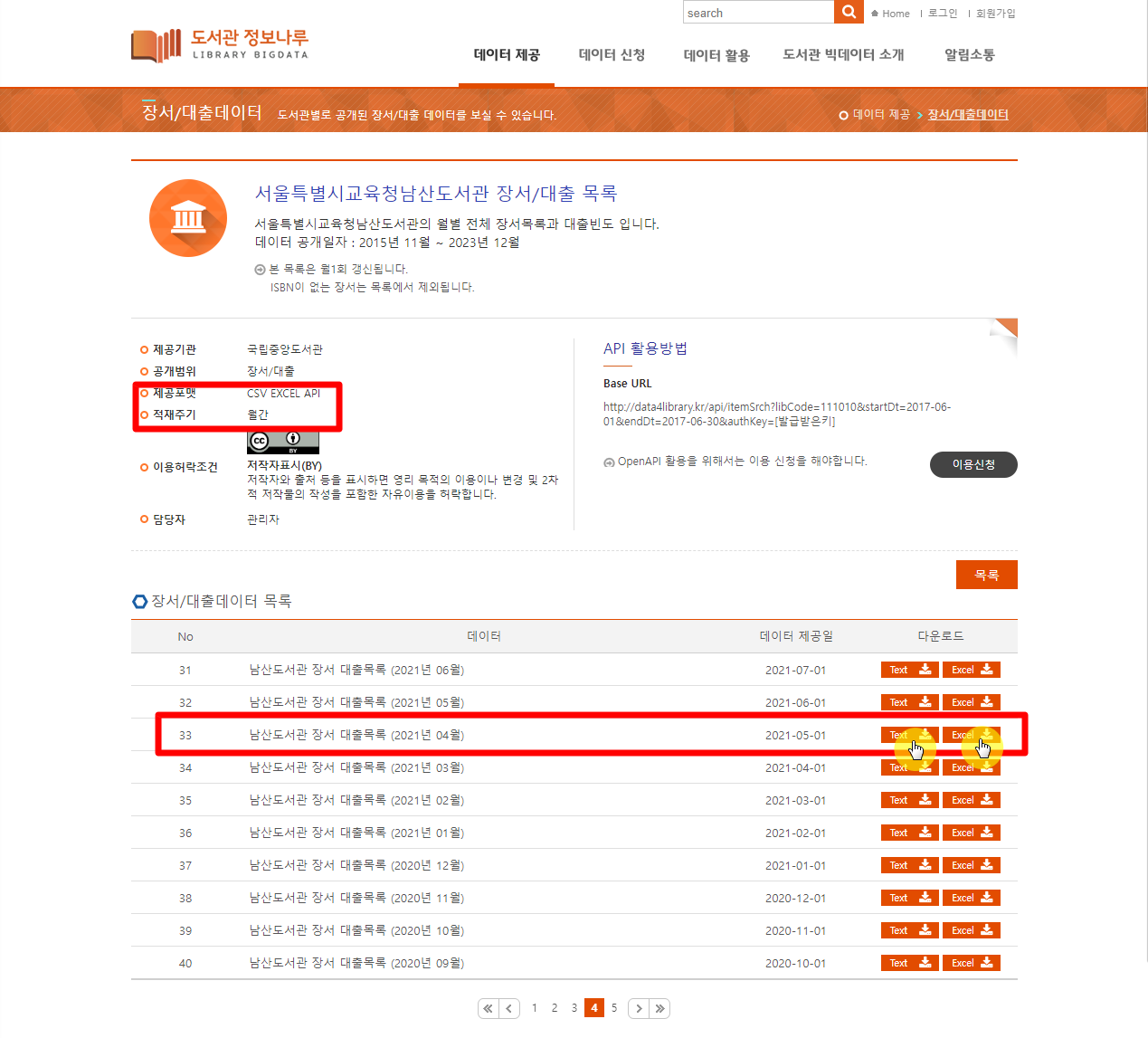
도서관 정보나루
전국 서울 부산 대구 인천 광주 대전 울산 세종 경기 강원 충북 충남 전북 전남 경북 경남 제주 전체 영유아(0~5) 유아(6~7) 초등(8~13) 청소년(14~19) 20대 30대 40대 50대 60대 이상 전체 영유아(남) 영유
www.data4library.kr
- 도서관별 대출 데이터 확인

- 남산도서관 대출 데이터 확인

- 제공포맷 : CSV, 엑셀, API
- 적재주기 : 월간
- 2021년 04월 Text, Excel 다운로드
코랩에서 데이터 확인하기
CSV (Comma-Seperated Values)
- 콤마(,) 로 구분된 텍스트 파일
- 한 줄이 하나의 record
- record 는 콤마로 구분된 여러 field 로 구분
- 행 row 은 CSN 파일에서 한 줄로 표현
- 열 column 은 콤마로 구분
코랩에 데이터 다운로드하기: gdown 패키지
- 빈 코랩 노트북 생성
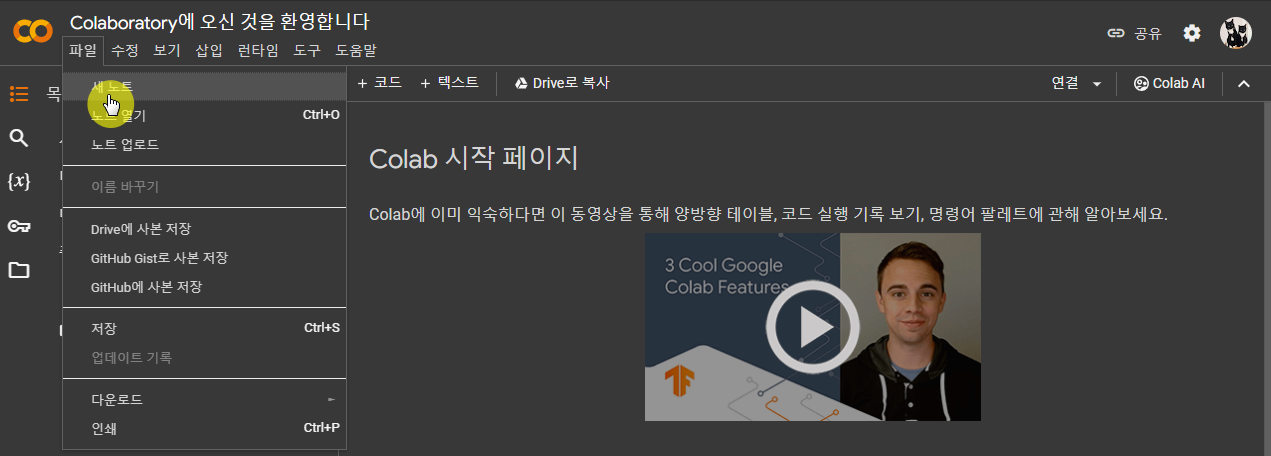
- gdown 패키지를 임포트하는 코드를 작성하고 실행
import gdown
gdown.download('https://bit.ly/3eecMKZ',
'남산도서관 장서 대출목록 (2021년 04월).csv', quiet=False)
- 다운로드 코드가 노트북에 저장 > 노트북을 다시 열 때 CSV 파일이 자동으로 준비
내 컴퓨터 파일을 업로드하기
파이썬으로 CSV 파일 출력하기
- open( ) 함수로 텍스트 파일 읽기
- with 문으로 파일을 연 다음 readline ( ) 메서드로 파일에서 한 줄을 읽어서 출력
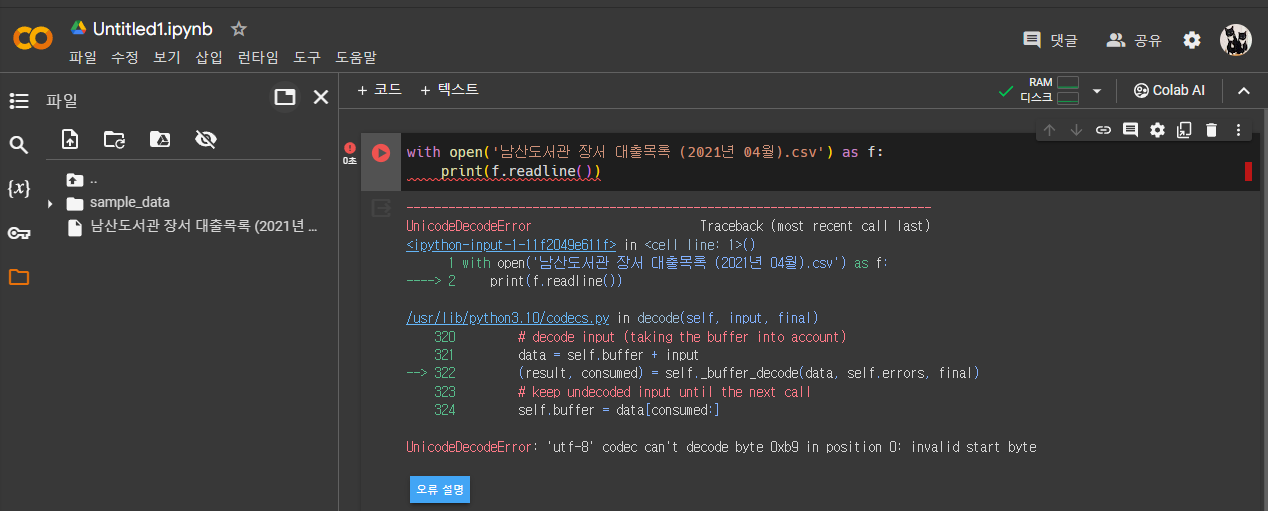
with open('남산도서관 장서 대출목록 (2021년 04월).csv') as f:
print(f.readline())
- UnicodeDecodeError 에러
- 파이썬의 open () 함수는 기본으로 텍스트 파일이 UTF-8형식으로 저장되어 있다고 가정
- 한글은 EUC-KR을 사용하는 경우가 많음
파일 인코딩 형식 확인하기 : chardet.detect( ) 함수
- chartdet 패키지의 chardet.detect( ) 함수 : 문자 인코딩 방식 확인
- open ( ) 함수로 텍스트 파일을 열 때 mode 매개변수를 바이너리 읽기 모드인 'rb'로 지정
- 바이너리 모드로 지정 > 문자 인코딩 형식에 상관없이 파일을 열 수 있음
- 텍스트 파일을 바이너리 모드로 읽으면 모든 글자를 1바이트로 인식 > 한글과 같은 유니코드 문자를 올바르게 출력할 수 없음
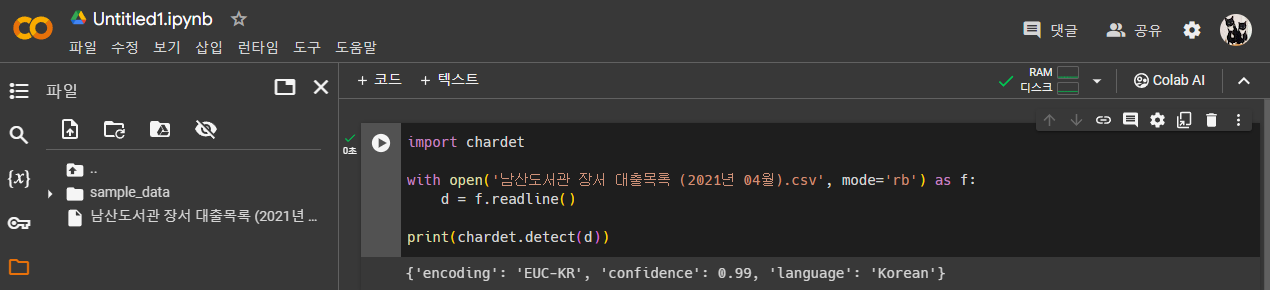
import chardet
with open('남산도서관 장서 대출목록 (2021년 04월).csv', mode='rb') as f:
d = f.readline()
print(chardet.detect(d))- csv 파일은 UTF-8 이 아니라 EUC-KR 로 인코딩
인코딩 형식 지정하기
- open ( ) 함수로 파일을 열 때 encoding 매개벼누로 인코딩 형식을 EUC-KR 로 지정
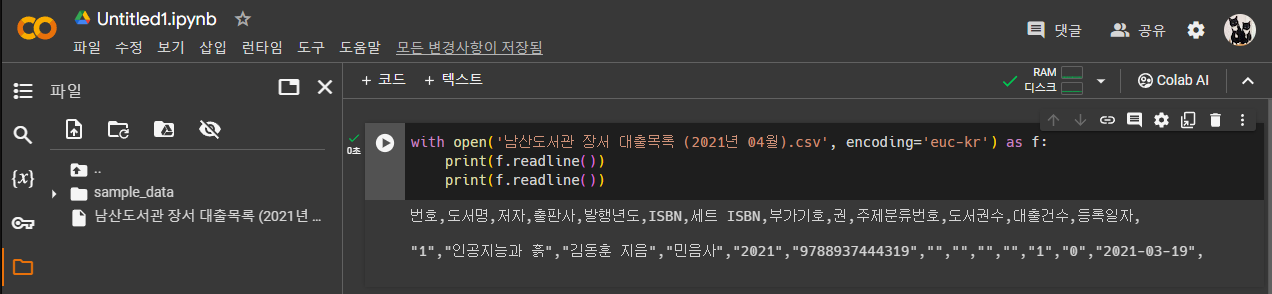
with open('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='euc-kr') as f:
print(f.readline())
print(f.readline())
데이터프레임 다루기 : 판다스
- CSV 파일을 읽어 데이터프레임 이라는 표 형식 데이터로 저장
- 표 형식 데이터 : 행과 열로 구성된 데이터 구조
- 시리즈
- 1차원 배열과 흡사한 판다스의 객체
- 한 종류의 데이터만 포함
- 데이터프레임
- 데이터를 가로 세로로 나열한 2차원 배열과 비슷
- 열마다 다른 데이터 타입을 사용할 수 있음
- 같은 열에 있는 데이터는 모두 같은 종류이어여 함
- 데이터프레임의 한 열을 따로 선택하면 시리즈 객체하로 할 수 있음
CSV파일을 데이터프레임으로 읽기 : read_csv( ) 함수
- read_csv( ) 함수를 호출하려면 판다스를 임포트해야 함
- pandas.read.csv( ) > pd.read_csv( )
- as 키워드로 임포트할 패키지 이름을 pd로 변경
import pandas as pd
df = pd.read_csv('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='euc-kr')
- 판다스는 CSV 파일을 읽을때 메모리를 효율적으로 사용하기 위해 CSV 파일을 조금씩 읽는데 이 때 자동으로 파악한 데이터 차입이 달라지면 경고 발생
DtypeWarning: Columns (5,6,9) have mixed types. Specify dtype option on import or set low_memory=False

- low_memory 매개변수를 false 로 지정 > 파일을 나누지 않고 한 번에 읽기
df = pd.read_csv('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='euc-kr', low_memory=False)
- head( ) 메서드로 데이터프레임의 처음 다섯 개 행을 확인
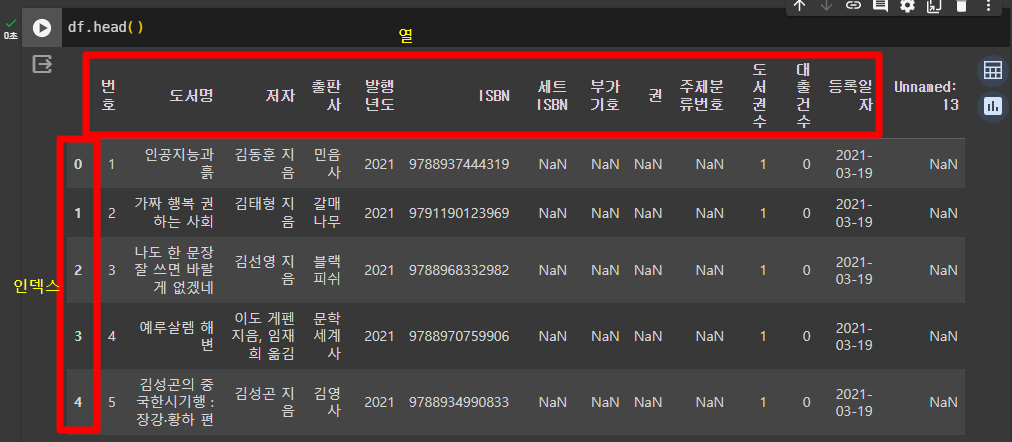
- 인덱스
- 데이터프레임의 첫 번째 열
- 판다스는 행마다 0부터 시작하는 인덱스 번호를 자동으로 부여
- CSV의 첫 번째 행은 열 이름으로 인식
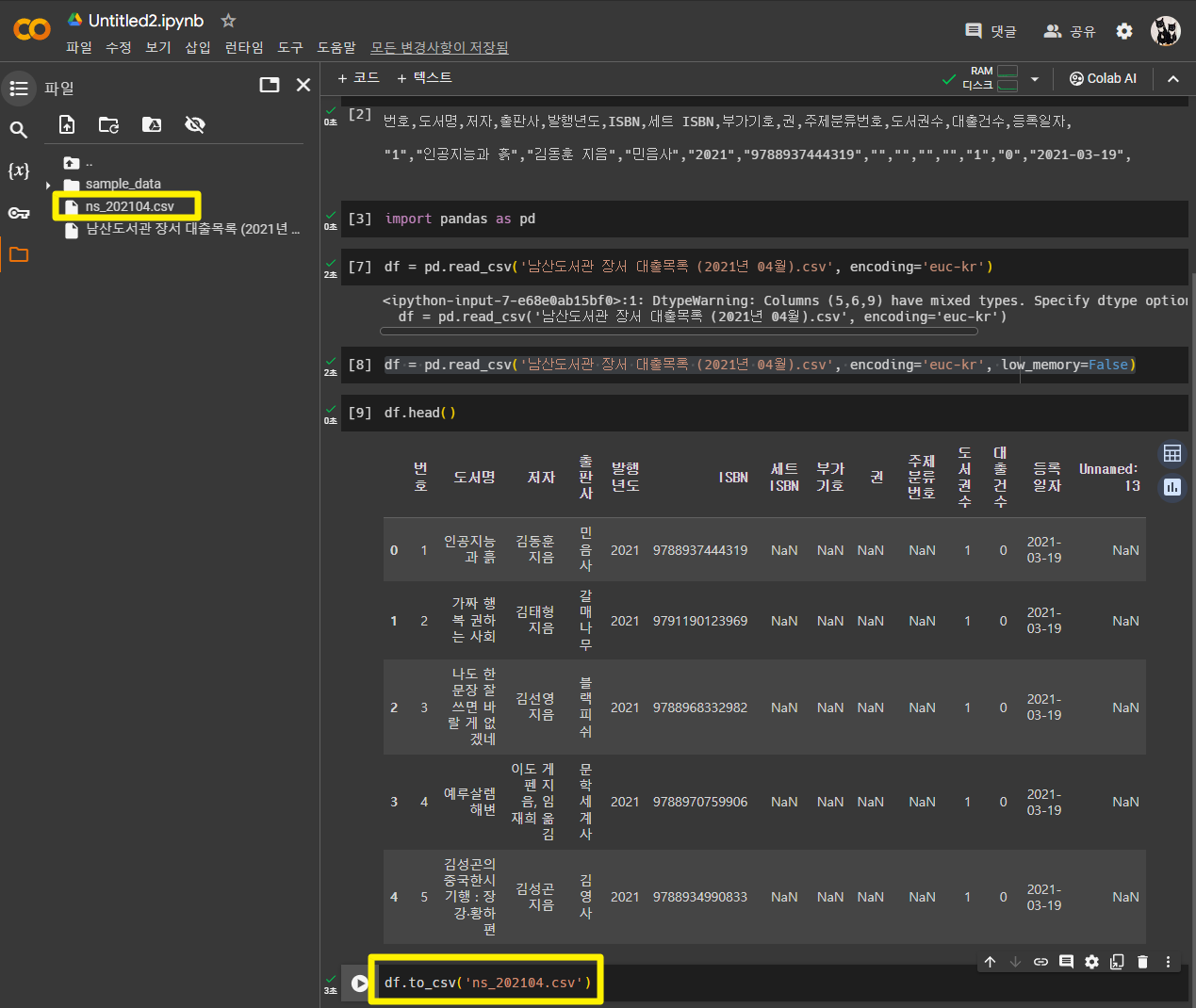
데이터프레임을 CSV 파일로 저장하기 : to_csv( ) 메서드
- 자동으로 UTF-8 로 저장 > open( ) 함수로 파일을 읽을 때 따로 encoding 매개변수를 사용하지 않아도 됨
- readline( ) 메서드를 세 번 적는 대신 for 문으로 세번 반복
- end=' ' 를 지정 > 줄바꿈 문자 출력 안함 > CSV 파일을 저장한 그대로 출력
with open('ns_202104.csv') as f:
for i in range(3):
print(f.readline(), end='')
- CSV 파일을 다시 데이터프레임으로 출력
ns_df = pd.read_csv('ns_202104.csv', low_memory=False)
ns_df.head()- 인덱스가 다시 생성되면서 'Unnamed:0' 이라는 첫번째 열과 중복
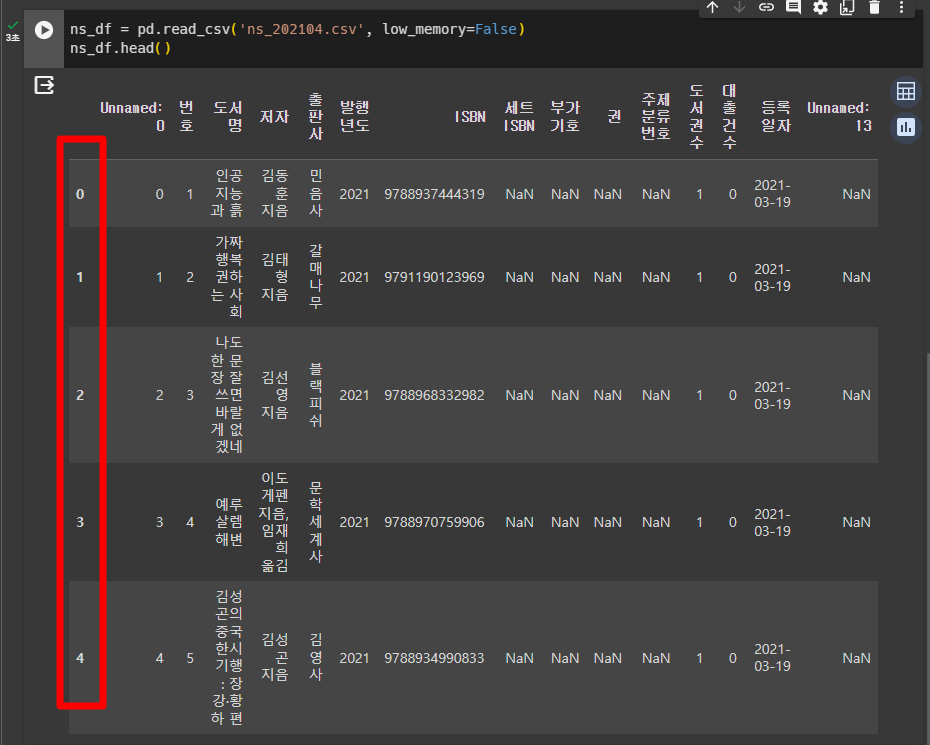
- index_col 매개변수
- CSV 파일에 인덱스가 이미 있다는 것을 알려 줌
- 첫번째 열에 인덱스가 있으므로 0으로 지정
ns_df = pd.read_csv('ns_202104.csv', index_col=0, low_memory=False)
ns_df.head()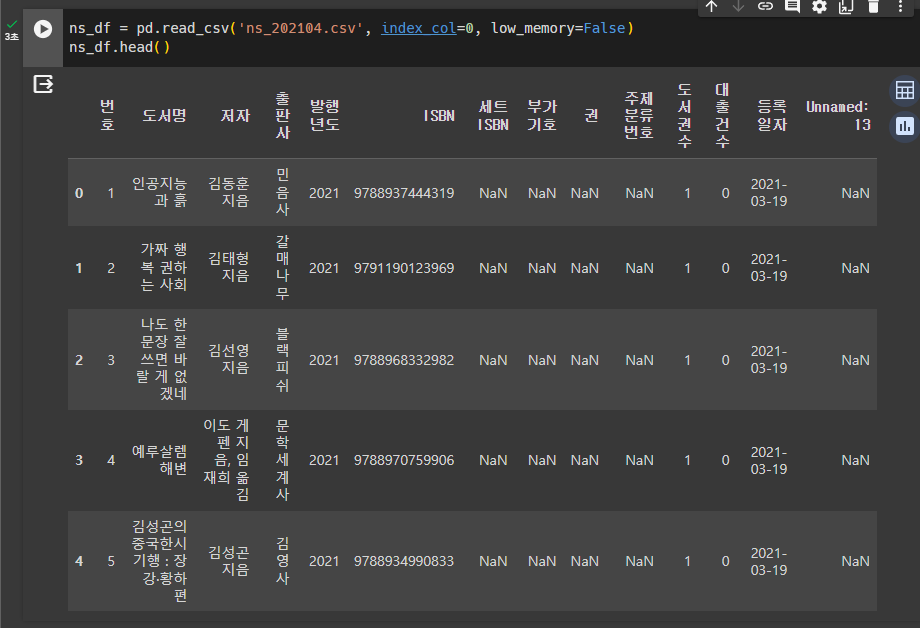
4. 판다스 read_csv() 함수의 매개변수 설명이 옳은 것은 무엇인가?
- header 매개변수의 기본값은 1로 CSV 파일의 첫 번째 행을 열 이름으로 사용합니다.
- names 매개변수에 행 이름을 리스트로 저장할 수 있습니다.
- encoding 매개변수에 CSV 파일의 인코딩 방식을 지정할 수 있습니다.
- dtype 매개변수를 사용하려면 모든 열의 데이터 타입을 지정해야 합니다.
'혼자 공부하는 데이터분석' 카테고리의 다른 글
| [ 혼공데분 - Chapter02 ] 데이터 수집하기 - 웹 스크래핑 사용하기 (0) | 2024.01.14 |
|---|---|
| [ 혼공데분 - Chapter02 ] 데이터 수집하기 - API 사용하기 (0) | 2024.01.10 |
| [혼공데분] 01 데이터분석을 시작하며 - 2) 구글 코랩과 주피터 노트북 (0) | 2024.01.02 |
| [혼공데분] 01 데이터분석을 시작하며 - 1) 데이터 분석이란 (0) | 2024.01.02 |
'혼자 공부하는 데이터분석' Related Articles
more



Comments